試行錯誤して学んでいく卓球ロボ
これまでにも卓球ロボは存在してきましたが、今回開発されたのは、「試行錯誤を繰り返して学習していく卓球ロボ」です。
最初にチームは、本物のロボットではなく、コンピュータ内に仮想のロボットアームと卓球台を作成。
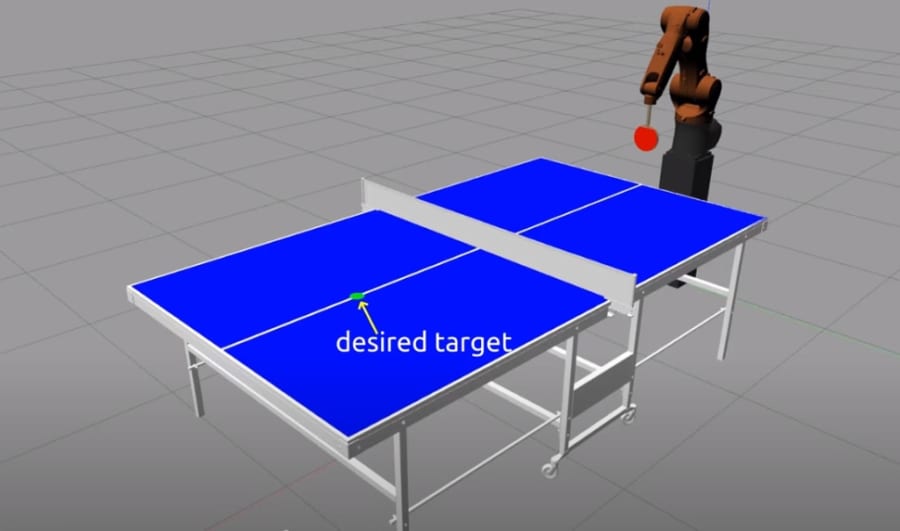
コンピュータシミュレーションで、ラケットの速度と向きがボールの軌道にどのような影響を与えるか機械学習させました。
そして失敗と改善を積み重ねた結果、シミュレーションでは確実にピンポン玉を返せるようになりました。
その後チームはこのアルゴリズムを、卓球ラケットをもった本物のロボットアームに導入。
現実世界で人間とラリーできるよう、さらに学習させたのです。

卓球ロボは、2台のカメラを使ってピンポン玉の位置を7ミリ秒ごとに追跡し、その情報に基づいて、ロボットアームをどこに動かすか決定しています。
現段階では、卓球ロボが意図したポイントから平均24.9cm以内の場所に打ち込むことが可能。
コンピュータシミュレーションより精度は落ちますが、それでも「わずかに劣る」程度のようです。

最終的に卓球ロボは、学習に合計90分(シミュレーションと現実)を費やしただけでした。
非常に短時間ですが、人間と対戦できるほどに成長したのです。